
С анализом множеств сталкивается каждый разработчик, который пересекает рубеж от новичка к более продвинутому разработчику. Действительно, один из сложных моментов в изучении Qlik — создание выражений для анализа множеств (Set Analysis), но именно это открывает множество возможностей в разработке приложений, поэтому в этой статье рассмотрим основы теории Set Analysis.
Анализ множеств: введение
Анализ множеств (Set Analysis) в Qlik позволяет обрабатывать ограниченный набор данных, на которые не влияют текущие выбранные данные (фильтры, которые мы применили к данным в нашем приложении). Фактически, множества задают контекст в выражении, в разрезе которого мы анализируем данные.
Set Analysis очень удобен при выполнении различных сравнений, как, например сравнение продуктов, пользующихся наибольшим спросом с продуктами, пользующимися наименьшим спросом, или сравнение показателей этого года с показателями прошлого года.
Давайте представим, что мы начинаем работать с документом, выбрав в списке 2010 год. В таком случае, агрегирования основаны на этой выборке, и в диаграммах показаны значения, относящиеся только к этому году. При выполнении новых выборок диаграммы обновляются соответственно. Агрегирования выполняются в отношении множества возможных записей, определенных текущими выборками.
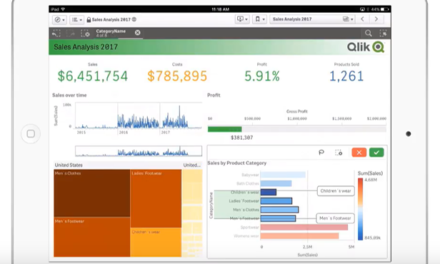
Когда мы используем выражение с анализом множеств внутри диаграммы, то график будет вычисляться на основе набора данных внутри выражения, а не на основе выбранных зеленых значений.

Так, здесь показаны продажи по Quebec, хотя эти значения не выбраны в панели фильтрации данных.

Сравнение данных по времени будет очень сложным без применения концепции анализа множеств.

Итак, здесь мы смотрим на данные месяц текущего года к месяцу прошлого года.

Как работает анализ множеств
Надо отметить, что синтаксис анализа множеств в Qlik не так прост. Выражения анализа множеств всегда заключаются в фигурные скобки с использованием функций агрегирования, таких как sum(), avg(), max(), min(), а также only().

НА ЗАМЕТКУ! Только в анализе множеств в Qlik используются фигурные скобки.
Итак, типовая структура выражения с анализом множеств имеет следующую структуру:
- Identifiers. Один или несколько идентификаторов определяют отношение между выражением множества и тем, что оценивается в остальной части выражения. Простое выражение множества состоит из одиночного идентификатора, например знака доллара США {$}, что означает все записи в текущей выборке.
- Operators. Если идентификаторов несколько, для обновления множества данных используется один или несколько операторов. Обновление выполняется путем определения способа объединения множеств данных, представленных идентификаторами, для создания подмножества или супермножества, например.
- Modifiers. Для изменения выборки в выражение множества можно добавить один или несколько модификаторов. Модификатор можно использовать самостоятельно или для изменения идентификатора для фильтра множества данных.
- Элементы списка – определенная выборка, связанные с модификатором поля
Идентификаторы
Идентификаторы определяют отношение между выражением множества и значениями поля или оцениваемым выражением. Типовые идентификаторы собраны в таблице ниже:
| Идентификатор | Описание |
| 1 | Представляет полное множество всех записей в приложении, независимо от выборок. |
| $ | Представляет записи текущей выборки. Выражение множества {$}, таким образом, эквивалентно неутверждению выражения множества. |
| $1 | Представляет предыдущую выборку. $2 представляет предыдущую предпоследнюю выборку и т. д. |
| $_1 | Представляет следующую (стоящую впереди) выборку. $_2 представляет следующую предпоследнюю выборку и т. д. |
| BM01 | Можно использовать любой ID закладки или имя закладки. |
| MyAltState | Можно ссылаться на выборки, выполненные в другом состоянии, по их имени состояния. |
Операторы
Операторы используются для включения, исключения или пересечения частей целых множеств данных. Все операторы используют множества в качестве операндов и в результате возвращают множество.
Типы операторов
+
Объединение. Данная операция возвращает множество, состоящее из записей, принадлежащих любому из двух операндов множества. 
–
Исключение. Данная операция возвращает множество записей, принадлежащих первому из двух операндов множества. Также при использовании в качестве унарного оператора, она возвращает дополнительное множество.

*
Пересечение. Данная операция возвращает множество, состоящее из записей, принадлежащих обоим операндам множества.

/
Симметрическая разность. Данная операция возвращает множество, состоящее из записей, принадлежащих любому из операндов множества, но не обоим.

Модификаторы
Модификаторы используются для внесения дополнений или изменений в выборку. Подобные изменения могут быть записаны в выражении множества. Модификатор состоит из нескольких имен поля, после каждого указана одна или несколько выборок, которые можно выполнить в поле. Модификаторы начинаются и заканчиваются угловыми скобками <>.
Элемент списка и расширенный поиск
Наиболее распространенным случаем является выборка, основанная на списке значений поля, заключенном в фигурные скобки, значения разделены запятыми. Например: <Year = {2007, 2008}>. Здесь фигурные скобки определяют множество элементов, в котором элементы могут быть значениями поля или поисками значений поля. Поиск всегда определяется использованием двойных кавычек. Например, элемент <Ingredient = {«*Garlic*»}> выберет все ингредиенты, включая строку «чеснок». В поиске учитывается регистр, поиск выполняется для всех исключенных значений.
Специальные элементы: P() и E()
P() и E() – специальные элементы, которые помогают определить множество значений поля с помощью вложенного определения множества. Они представляют множество элементов возможных значений и исключенные значения поля, соответственно. В скобках можно указать одно выражение множества и одно поле. Например: P({1} Customer). Эти функции не могут использоваться в других выражениях.
Эта была общая часть по работе с анализом множеств в Qlik. В следующий раз расскажу в примерах, как работать с Set Analysis, а пока предлагаю воспользоваться библиотекой статей по анализу множеств, доступной здесь на Data-Daily:
- Шпаргалка по анализу множеств: Set Analysis в QlikView
- Анализ множеств в QlikView: Звездные равенства
- Анализ множеств для получения скрытых ответов в Qlik
На этом все на сегодня! Отличных вам разработок с Qlik.



{kind=link}
Свежие комментарии