
Интеграция Qlik и поисковой платформы Solr позволяет организовать работу с большими данными и анализировать неструктурированные данные. Solr индексирует любой текст, в том числе файлы XML, JSON, PDF, Word, Excel, поэтому найти любые текстовые данные с этим инструментом становится очень просто. Далее расскажу о возможностях интеграции Solr и Qlik, а также дам краткую инструкцию по их совместной настройке.
Solr: что это такое и как работает вместе с Qlik
Solr — платформа полнотекстового поиска с открытым исходным кодом, основанная на проекте Apache Lucene. Её основные возможности: полнотекстовый поиск, подсветка результатов, динамическая кластеризация, интеграция с базами данных, обработка документов со сложным форматом.
Прежде, чем рассмотреть вопрос совместной работы Qlik и Solr, давайте рассмотрим типовой запрос Solr:

Здесь собраны следующие данные:
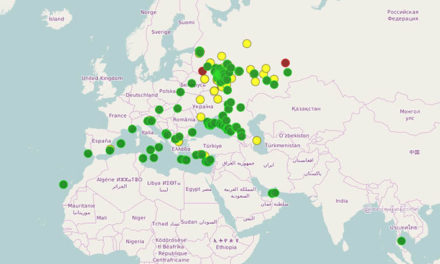
- Данные электронной почты американской энергетической корпорации Enron в 2000.
- Данные загружены в кластер Cloudera и проиндексированы в Solr.
- После загрузки данных выполнено несколько запросов.
В таких запросах возник большой вопрос – как увеличить скорость обработки запросов, поскольку средняя скорость ожидания составляла 10-15 минут на отдельный вопрос, поэтому решили найти альтернативу этой скорости ответа в лице Qlik REST Connector.
Qlik
Так, решили использовать Qlik REST Connector для подключения к Solr.
Итак, для подключения к данным Solr в интерфейсе Qlik используются следующие настройки:

В итоге, мы объединили данные фондовой биржи и текстов сообщений электронной почты. Интересно, что со снижением стоимости акций компании, увеличивается количество сообщений электронной почты, а где-то видно предумышленное удаление переписки между сотрудниками.
НА ЗАМЕТКУ! Enron – компания, которая, по версии Forbes, входит в список ТОП-10 известных корпораций-мошенников. Эта американская энергетическая компания, обанкротившаяся в 2001 году, в которой до банкротства работало около 22 000 сотрудников в 40 странах мира, и она являлась одной из ведущих в мире компаний, в таких областях как производство электроэнергии, транспортировка газа, газоснабжение, связь и целлюлозно-бумажное производство. В конце 2001 года стало известно, что информация о финансовом состоянии компании в значительной степени была сфальсифицирована с помощью бухгалтерского мошенничества, известного как «Дело Энрон».

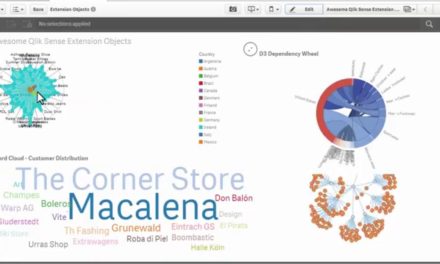
Использование нескольких типов визуализации, позволяет сделать обоснованный вывод о том, что часть сообщений была удалена из переписки.
Погружаясь дальше в данные, мы можем получить информацию вплоть до имени отправителя и наиболее часто используемых словах в сообщениях.

Далее у нас есть таблица связанных имен и текстовых фраз. На заключительной вкладке мы можем просмотреть полное содержание писем.

QIX API и Solr
Пример выше – это лишь один из способов работы с большими данными с помощью Qlik. Теперь давайте несколько перевернем условия поиска. Будем идти не от готовых визуализаций, а будем задавать поисковые слова и наблюдать за динамическим изменением аналитики. Вводим интересующую нас имя и фамилию сотрудника компании:

Через API создается приложение с визуализацией.

Через соединение REST к Solr, создаются и загружаются данные в память, а затем генерируется веб-приложение с использованием bootstrap.js и AngularJS.

Веб-приложение использует движок Qlik, поэтому все выборки активны, а все графики построены на html и d3js.
Что хочется отметить в итоге? Solr имеет неогорчённые возможности в области индексации неструктурированных данных, а Qlik позволит анализировать эти данные «на лету»!
На этом все на сегодня! Отличных вам разработок с Qlik.




{kind=link}
Свежие комментарии