
| Хранение | Аналитика | Визуализация |
 |
||
Непрерывный рост данных и увеличение скорости их генерации порождают проблему их обработки и хранения. Неудивительно, что тема Big Data является одной из самых обсуждаемых в современном ИТ-сообществе.
Сегодня рассмотрим возможности аналитики больших данных для оценки особенностей потребительского поведения, а также узнаем, как используя эту информацию, выбрать точки продаж ритейл-сети.
В данной статье будем опираться на теорию аналитики потребительской корзины, которая гласит, если покупатель берет определенную группу товаров, он, вероятно, купит и другую группу ассоциированных товаров.
Результаты, полученные с помощью анализа рыночной корзины, позволяют оптимизировать ассортимент товаров и запасы, а также управлять размещением товаров в торговых залах, увеличивать объемы продаж за счет предложения клиентам сопутствующих товаров. Например, если в результате анализа будет установлено, что совместная покупка макарон и кетчупа является типичным шаблоном потребительского поведения, то разместив эти товары на одной и той же витрине можно «спровоцировать» покупателя на их совместное приобретение.
Итак, на какие вопросы можно получить ответы при помощи аналитики потребительской корзины:
- Какие товары в других категориях берут с целевыми товарами группы.
- Какое влияние нового товара на связанные группы товаров.
- Каким будет влияние, если исключить связанный товар.

В ответах на эти вопросы нам поможет связка из нескольких ИТ-продуктов:
- библиотеки машинного обучения Spark,
- Cloudera
- и Qlik Sense.
Но для начала, давайте рассмотрим, какие есть особенности у Qlik, чтобы работать с большими данными? Qlik легко интегрируется с таким ПО как Cloudera, а возможность бесшовной интеграции с пакетом R превращает Qlik в инструмент предикативной аналитики, тем самым, мы можем переходить от уровня традиционной аналитики к аналитике в режиме реального времени и Machine Learning.
- Аналитика in-memory: Возможность аналитики нужны[ срезов данных, можем убрать все лишнее.

- Прямые/живые запросы: Иногда нужно работать не с отдельным срезом данных, а со всем объемом, тогда можно использовать режим живых запросов Qlik. Скорость работы будет напрямую зависеть от источников данных.

- Создание приложение по запросу: Можно составить наборное приложение самому пользователю.

- API – новый уровень доступа к данным: Доступ к данным через API позволяет управлять потоками данных, смешивая аналитику в режиме реального времени и ретроспективных данных.
Итак, теперь вернемся к нашему примеру аналитики потребительской корзины:
Перейти к готовому решению, созданному для ритейлеров с сотнями и тысячами магазинов:
В этом примере у нас есть набор данных от ритейлеров по покупкам. Сырые данные обрабатываются в Spark для выстраивания связей между покупками, результат поступает в Impala. Обработанные данные поступают в приложение Qlik.
Объем данных по потребительской корзине:
- 208 миллионов сырых строк транзакций?
- 90k вычисляемых комбинаций покупок,
- а также 238k продуктовых ассоциативных правил, полученных на основе библиотеки машинного обучения Spark.
НА ЗАМЕТКУ! Cloudera — американская компания, разработчик связующего программного обеспечения, выпускающая коммерческую версию программного каркаса Apache Hadoop.
Наш набор данных в приложении состоит из:
1) Данные за последние три года.
2) 4,500 SKU с именами продуктов, категориями, брендами и компаниями.
3) 100 миллионов сырых данных в полном объеме, хранимых в Hive.
4) Запущенный алгоритм Data Mining, который называется поиск ассоциативных правил в наборе данных. Data Mining начался именно с аналитики потребительской корзины. Анализ рыночной корзины — процесс поиска наиболее типичных шаблонов покупок в супермаркетах. Он производится путем анализа баз данных транзакций с целью определения комбинаций товаров, связанных между собой. Иными словами, выполняется обнаружение товаров, наличие которых в транзакции влияет на вероятность появления других товаров или их комбинаций.
Алгоритм работает внутри Spark, чтобы сгруппировать смежные товары, которые с высокой долей вероятности покупатель приобретет вместе. Метод записан в Scala, с использованием библиотеки Spark: http://spark.apache.org/docs/latest/mllib-frequent-pattern-mining.html
5) Ассоциативные правила хранятся в Hive.
НА ЗАМЕТКУ! Для решения задачи анализа рыночной корзины используются ассоциативные правила вида «если… то…». Например, «если клиент купил пиво, то он купит и чипсы». Каждая покупка именуется «транзакцией», на основании большего набора таких транзакций и строят исследования поведения клиента.
6) Основной набор данных отправляется в Qlik Sense.
Модель данных в нашем примере выглядит таким образом:

Итак, все данные с ассоциативными правилами переданы в Qlik Sense, а мы можем создать историю данных:
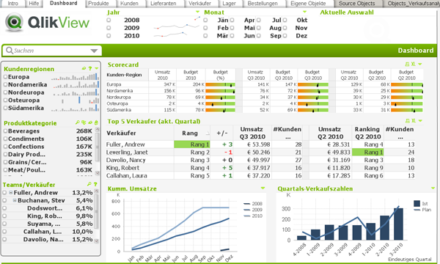
Это приложение по аналитике потребительской корзины создано для национальной сети ритейловых магазинов, которая продается тысячи SKU в более чем 758 магазинах сети. Они продают одинаковый ассортимент в каждом магазине. Давайте откроем лист с результатами продаж, чтобы понять, каково положение дел.
Воспользуемся глобальным поиском для выбора нужного временного диапазона. Найдем результат по октябрю 2015.
Прогнозная аналитика в этом случае помогает нам определить связи в данных, которые может не заметить человек. Это может нам помочь в увеличении кросс-продаж.
Так, ритейлер получил возможность отследить, какие товары продаются вместе, а все срезы данных можно посмотреть в приложении Qlik. Давайте откроем лист ассоциативных правил, посмотрим данные на год вперед. Воспользуемся глобальным поиском по октябрю 2016

Через анализ множеств мы посмотрим связанные продажи:

Мы видим здесь связи между продуктами. Также региональный менеджер, например, здесь сможет выделить данные только по своему региону и отследить, какие изменения идут по подведомственной ему территории, а также как повлиял, например, запуск нового продукта на продажи других товаров.
Лист с прогнозными правилами сможет нам показать примерный объем продаж в натуральных и денежных единицах именно для продуктовых комбинаций.
ИТОГИ
Помните как пару лет назад все только и делали, что говорили – большие данные – это будущее. Теперь можно точно сказать – это будущее уже наступило, у нас есть не только инфраструктура и готовое ПО, но и возможность скомбинировать продукты, предложенные рынком, чтобы получить бизнес-результат, реальную пользу для дела. Теперь мы переходим от слов «большие данные» к реальным бизнес-кейсам.
Дополнительные статьи по теме:



{kind=link}
Свежие комментарии