
Решил написать о том, как получить пользу из больших данных при помощи связки Cloudera + Qlik Sense.
Расскажу о том, как Qlik Sense работает с распределенной файловой системой HDFS (Hadoop) через хаб данных Cloudera. Итак, к вашему изучению – краткая инструкция по настройке совместной работы Qlik Sense и Cloudera.
Интеграция
Один из первых способов подсоединения Qlik к CDH — через ODBC. У Qlik есть бесплатный Apache Hive ODBC connector и Impala ODBC connector:
Коннекторы Cloudera позволяют Qlik Sense получить доступ к данным Hadoop через SQL-запросы к движкам Impala или Hive. Данные могут загружаться как частями (Hive connector) или в режиме реального времени через Qlik Direct Discovery (Impala connector).

Установка
Cloudera QuickStart VM позволяет быстро начать работу через консоль управления Cloudera Manager:
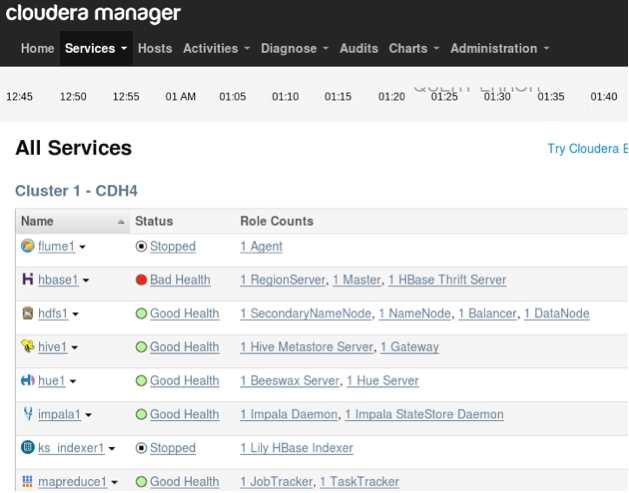
Затем настраиваем Hue.
После того, как подключение к данным установлено или данные загружены, Qlik Sense подключается к Cloudera по ODBC, используя драйвер Impala ODBC.
Вам нужно будет узнать IP-адрес среды Cloudera. Например, для Cloudera QuickStart VM, IP-адрес через команду ifconfig:
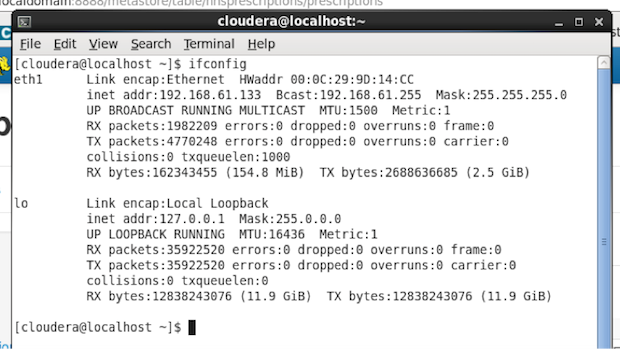
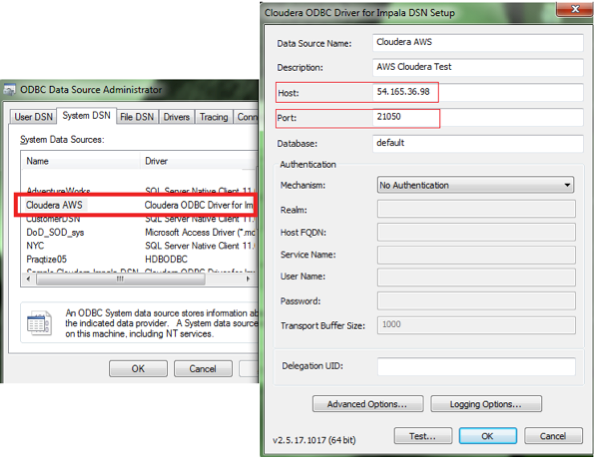
Вот такие настройки нам будут нужны: IP-адрес и номер порта, ODBC DSN, который использует коннектор Impala ODBC.
Анализ данных
Вообще, как было уже упомянуто выше, Cloudera в связке с Qlik Sense выгружает данные либо в режиме реального времени (при помощи Qlik Direct Discovery), либо порционной загрузки в in-memory, или еще один вариант – смешанный режим.
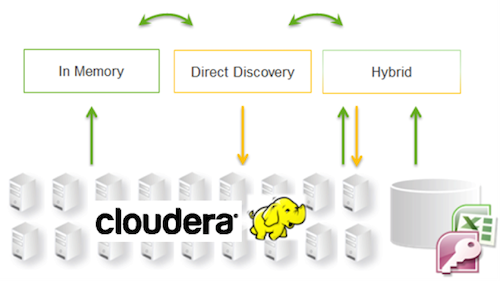
Для гибридной аналитики Qlik Sense автоматически определяет, какие данные обрабатываются в памяти, а какие подгружаются в реальном времени при помощи Direct Discovery. Для обработки данных в режиме реального времени используется команда (DIRECT QUERY).
После того, как в приложении сделаны выборки, связанные значения данных полей Direct Discovery, будут использоваться для всех запросов. С каждой выборкой, диаграммы Direct Discovery будут пересчитываться.
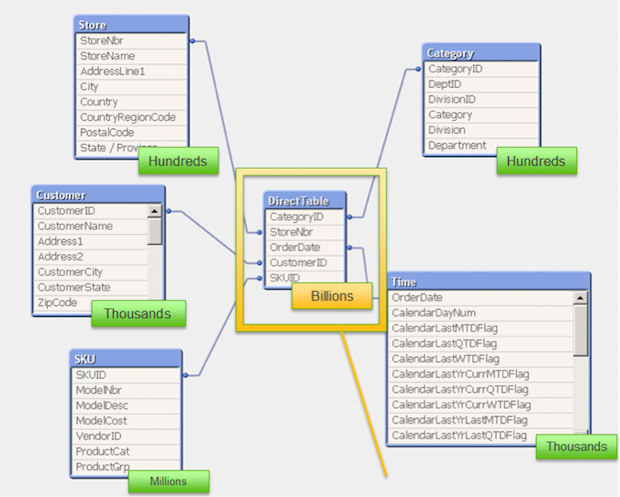
Как распределяются данные в Qlik при работе с Hadoop:
- Поля, отмеченные какDIMENSION, загружаются в память как символьные таблицы, чтобы можно было их использовать для быстрых выборок. Когда приложение загружается, Qlik загружает только уникальные значения по каждому полю. Если поле DIMENSION нужно отделить от остальной части модели данных, нужно использовать ключевое слово DETACH.
- Поля, отмеченные какMEASURE и DETAIL, работают только как табличный источник данных внутри Hadoop, они не являются частью данных, вычисляемых в памяти. Они вписаны в модель данных на уровне мета-данных, для того чтобы их можно было использовать в графиках и диаграммах. Поле DETAIL не входят в выражения диаграмм.
- Поля NATIVE используются на самом низком уровне, без агрегирования. В случае с реляционной базой данных, также может использоваться полеNATIVE.
Обычно ключевые слова в Direct Discovery выглядят как:
| 1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
DIRECT QUERY
DIMENSION SalesPersonID, OrderDate, NATIVE(‘month([OrderDate])’) as OrderMonth, NATIVE(‘Year([OrderDate])’) as OrderYear MEASURE SubTotal, TaxAmt, TotalDue DETAIL DueDate, ShipDate, AccountNumber, CreditCardApprovalCode, rowguid, ModifiedDate DETACH SalesOrderID, CustomerID FROM AdventureWorks.Sales.SalesOrderHeader; |
Функция Qlik Direct Discovery идет с поддержкой мульти-таблиц, то есть таблица Direct Discovery может рассматриваться как объединение нескольких таблиц в один источник данных. В одном и том же приложении можно использовать несколько таблиц Direct Discovery.
Вместо заключения
Качество Qlik Sense Direct Discovery зависит от следующих факторов:
- Качество запросов Direct Discovery к Cloudera напрямую зависит от качества сети, размера кластера, а также доступного объема памяти в узле.
- Важно использование супер-хранилища данных, таких как MySql vs. Derby, чтобы улучшить качество выполняемых запросов Direct Discovery.
На этом сегодня все!
Успехов вам в погружении в «большие данные»!




{kind=link}
Свежие комментарии