
Мы трепетно относимся к телефонным звонкам клиентов. И раз уж клиент позвонил, стараемся сделать все, чтобы довести его до ручки покупки. Да, мы используем передовые технологии: заказ обратного звонка, динамическое и статическое отслеживания звонков, их аудит, но в этот раз поговорим о приземленном анализе входящих звонков.
Немного экономики
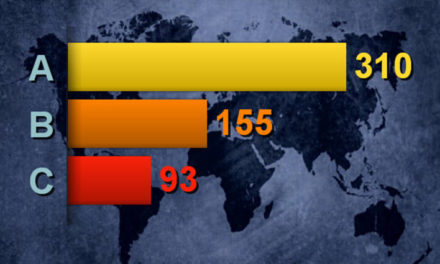
Примем стоимость перехода на сайт за 1$. Пусть конверсия посетителя сайта в звонящего составляет 10%. Тогда стоимость привлечения клиента составит 10$. Если мы оставляем без ответа 10 звонков клиентов в день (или 200 в месяц), значит, мы ежемесячно выкидываем 2000$.
ПроЛог
Мы установили себе телефонную станцию Asterisk и настроили хитрым образом маршрутизацию звонков. Например, звонок на линию продаж приходит оператору 1-й линии, и, если в течении 7 секунд оператор не ответил, звонок попадает операторам 2-й линии, если в течении 10 секунд — они не ответили, звонок уходит в отдел продаж. А если и там звонок не отработан, он уходит директору. Первое время после внедрения, телефон директора разрывался, но затем усилили команду операторов, разработали типовые скрипты работы с клиентами и телефон успокоился.
Немного истории
Астериск (Asterisk), согласно легенде, был придуман Марком Спенсером (Mark Spenser). Марк основал бизнес по оказанию бесплатных консультаций пользователям линукса и обнаружил отсутствие на рынке эффективного (доступного, открытого, гибкого, свободного, добавить желаемое) механизма распределения звонков по операторам-экспертам. Тогда он решил написать Астериск. Подробнее можно посмотреть там https://ru.wikipedia.org/wiki/Asterisk
Да, мы знаем, что существует огромное множество (платных и бесплатных) модулей для анализа логов Астериска (CDR reports, QueueMetrics и т.д.), но мы их не стали использовать потому, что:
- не хотели пускать аналитиков на боевой сервер (эти модули ставятся на сервер);
- лелеяли мечту прикрутить звонки к продажам в имеющейся аналитической системе отчетности (QlikView)/
Поэтому и решили изобрести велосипед. Вот что из этого получилось:
АрхеоЛог
Изучение логов, подобно занятиям археологией. Мы можем только догадываться, какие реальные события привели к формированию именно таких логов. У нас остаются материальные свидетельства в виде записей разговоров, но предпосылки событий, мысли участников остаются за кадром. Нам достались для анализа логи очередей, хотя возможно, вам удастся получить и более простые логи звонков.
Немного лирики
Изучая логи, находили странные последовательности событий. Например, сотрудник звонит с внутреннего номера в бухгалтерию. Бухгалтерия не отвечает. Звонок сваливается на оператора. После этого сотрудник общается с оператором несколько минут. О чём это я?
К счастью, есть структура логов очередей.
Астериск хранит логи обслуживания очередей в виде текстовых файлов queue_log в кодировке UTF-8 без заголовков с разделителем ‘|’. Продвинутый случай, когда логи сбрасываются в MySQL не рассматриваем, ибо он проще. Текстовые логи имеют вид:
|
1 2 3 4 5 6 7 8 9 10 11 |
1438820821|NONE|NONE|NONE|CONFIGRELOAD| 1438834123|1438834115.282219|900|NONE|DID|CO1 1438834123|1438834115.282219|900|NONE|ENTERQUEUE|| |1 1438834133|1438834115.282219|900|Operator1|RINGNOANSWER|10000 1438834133|1438834115.282219|900|Operator2|RINGNOANSWER|10000 1438834133|1438834115.282219|900|NONE|EXITTIMEOUT|1|1|10 1438834133|1438834115.282219|901|NONE|DID|CO1 1438834133|1438834115.282219|901|NONE|ENTERQUEUE||4959371650|1 1438834137|1438834115.282219|901|Irina|CONNECT|4|1438834133.2826|3 1438834202|1438834115.282219|901|Irina|COMPLETECALLER|4|65|1| 1438834203|1438834115.282219|901|Irina|COMPLETEAGENT|4|66|1 |
Расшифровка полей
1) Дата время в Unix формате (количество секунд с 01.01.1970).
2) Идентификатор вызова.
3) Идентификатор очереди.
4) Идентификатор агента (оператора).
5) Название события.
6) Далее поля с 6 по 10 (как и 3 и 4) наполняются смыслом в зависимости от названия события (5).
В данном примере легко увидеть, что:
1) 06.08.15 в 00:27 произведена перезагрузка конфигурации сервера очередей.
2) 06.08.15 в 04:08 контрагент произвел звонок на линию CO1 с номера 4959371650 (так этот номер распознается на этой линии, на другой линии он может иметь префикс 7, а на третьей 8). Звонок попал в 900 очередь. Звонок раздавался одновременно у Operator1 и Operator2 10000мс, затем звонок покинул очередь по превышению времени ожидания 10с. Звонок вошел в очередь 901, откуда был извлечен оператором Irina через 4с. Разговор записывался по идентификатором 1438834133.2826. На 65 секунде разговора контрагент завершил звонок, а Irina на 66.
Немного заметок
1) Единицы измерения у разных событий могут различаться, например (секунды и милисекунды) и их надо приводить к единообразию.
2) Одно и то же поле хранит разные данные в зависимости от контекста.
3) Возникают неоднозначности (длительность разговора 65 и 66 секунд), которые нужно трактовать.
4) В номерах очередей странные значения (например, 111, при отсутствии 110), возможно мы не умеем их интерпретировать.
АстроЛог
Увидев ключ — идентификатор вызова, сразу возникла мысль сделать модель данных по схеме звезда.
Вот скрипт загрузки:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 |
REM Грузим логи в память для ускорения; QueueLog: LOAD rowno() as RecID, // на всякий случай, чтобы различать одинаковые записи @1, text(@2) as @2, @3, @4, @5, @6, @7, @8, @9, // может быть непустым!!! @10,// может быть непустым!!! @11 //@11 должен быть всегда пустой FROM [Queue_log\queue_log.*] (txt, utf8, no labels, delimiter is '|', msq) ; rem Формируем список внутренних звонков; InternalCall: LOAD DISTINCT @2 as InternalCallId Resident QueueLog Where @5='ENTERQUEUE' and len(@7)=3 // внутренние 3-Х значные звонки ; rem обрабатываем событие DID; DID: LOAD floor(@1/60/60/24+MakeDate(1970,1,1)) as DID.Date, frac((@1-43*365*24*60*60)/60/60/24) as DID.Time, Hour(frac(@1/(60*60*24))) as DID.Hour, //@1, @2 as CallId, @3 as DID.QueueName, //@4 as DID.ChannelName, //Всегда NONE //@5 as EventType, if(len(@6)>0,@6,'---') as DID.Line // что это? Resident QueueLog Where @5='DID' and @3<>989 // говорят что 989 - это тестовая линия and @3<>150 // логисты //and @3<>200 // Отдел продаж //and @3<>300 //операторы and @3<>400 // бухгалтерия //and len(@6)>0 // Исключая внутренние звонки and Not Exists(InternalCallId, @2) ; DROP Table InternalCall; mapCallTime: Mapping LOAD @2 as CallId, min(@1) as CallTime Resident QueueLog Where @5='DID' Group by @2 ; ENTERQUEUE: LOAD @1-ApplyMap('mapCallTime',@2,@1) as ENTERQUEUE.TimeShift, //frac(@1/60/60/24) as ENTERQUEUE.Time, @2 as CallId, @3 as ENTERQUEUE.QueueName,//, //@4 as ENTERQUEUE.ChannelName, //Всегда NONE //@5 as EventType, //@6, if(left(@7,1)='8' and len(@7)=11, '7' & mid(@7,2),if(len(@7)=10,'7' & @7, if(len(@7)>0 and @7<>'unknown',@7, Repeat('0',11)))) as ENTERQUEUE.Caller, @8 as ENTERQUEUE.Position Resident QueueLog Where @5='ENTERQUEUE' and Exists(CallId, @2) ; RINGNOANSWER: LOAD @1-ApplyMap('mapCallTime',@2,@1) as RINGNOANSWER.TimeShift, //frac(@1/60/60/24) as RINGNOANSWER.Time, @2 as CallId, @3 as RINGNOANSWER.QueueName, @4 as RINGNOANSWER.ChannelName, //@5 as EventType, floor(num#(@6)/1000) as RINGNOANSWER.RingTime Resident QueueLog Where @5='RINGNOANSWER' and Exists(CallId, @2) ; EXITEMPTY: LOAD @1-ApplyMap('mapCallTime',@2,@1) as EXITEMPTY.TimeShift, //frac(@1/60/60/24) as EXITEMPTY.Time, @2 as CallId, @3 as EXITEMPTY.QueueName, //Всегда 900 //@4 as EXITEMPTY.ChannelName, //@5 as EventType, @6 as EXITEMPTY.Position, @7 as EXITEMPTY.OrigPosition, @8 as EXITEMPTY.WaitTime Resident QueueLog Where @5='EXITEMPTY' and Exists(CallId, @2) ; CONNECT: LOAD @1-ApplyMap('mapCallTime',@2,@1) as CONNECT.TimeShift, //frac(@1/60/60/24) as CONNECT.Time, @2 as CallId, @3 as CONNECT.QueueName, //Всегда 900 @4 as CONNECT.ChannelName, //@5 as EventType, @6 as CONNECT.HoldTime, @7 as CONNECT.BridgedChannelUniqueId, @8 as CONNECT.RingTime Resident QueueLog Where @5='CONNECT' and Exists(CallId, @2) ; COMPLETEPICKUPER: LOAD @1-ApplyMap('mapCallTime',@2,@1) as COMPLETEPICKUPER.TimeShift, //frac(@1/60/60/24) as COMPLETEPICKUPER.Time, @2 as CallId, @3 as COMPLETEPICKUPER.QueueName, //Всегда 900 @4 as COMPLETEPICKUPER.ChannelName, //@5 as EventType, @6 as COMPLETEPICKUPER.HoldTime, @7 as COMPLETEPICKUPER.CallTime, @8 as COMPLETEPICKUPER.OrigPosition Resident QueueLog Where @5='COMPLETEPICKUPER' and Exists(CallId, @2) ; COMPLETEAGENT: LOAD @1-ApplyMap('mapCallTime',@2,@1) as COMPLETEAGENT.TimeShift, //frac(@1/60/60/24) as COMPLETEAGENT.Time, @2 as CallId, @3 as COMPLETEAGENT.QueueName, //Всегда 900 @4 as COMPLETEAGENT.ChannelName, //@5 as EventType, @6 as COMPLETEAGENT.HoldTime, @7 as COMPLETEAGENT.CallTime, @8 as COMPLETEAGENT.OrigPosition Resident QueueLog Where @5='COMPLETEAGENT' and Exists(CallId, @2) ; COMPLETECALLER: LOAD @1-ApplyMap('mapCallTime',@2,@1) as COMPLETECALLER.TimeShift, //frac(@1/60/60/24) as COMPLETECALLER.Time, @2 as CallId, @3 as COMPLETECALLER.QueueName, //Всегда 900 @4 as COMPLETECALLER.ChannelName, //@5 as EventType, @6 as COMPLETECALLER.HoldTime, @7 as COMPLETECALLER.CallTime, @8 as COMPLETECALLER.OrigPosition Resident QueueLog Where @5='COMPLETECALLER' and Exists(CallId, @2) ; ABANDON: LOAD @1-ApplyMap('mapCallTime',@2,@1) as ABANDON.TimeShift, //frac(@1/60/60/24) as ABANDON.Time, @2 as CallId, @3 as ABANDON.QueueName, //Всегда 900 //@4 as ABANDON.ChannelName, Всегда NONE //@5 as EventType, @6 as ABANDON.Position, @7 as ABANDON.OrigPosition, @8 as ABANDON.WaitTime Resident QueueLog Where @5='ABANDON' and Exists(CallId, @2) ; EXITWITHTIMEOUT: LOAD @1-ApplyMap('mapCallTime',@2,@1) as EXITWITHTIMEOUT.TimeShift, //frac(@1/60/60/24) as EXITWITHTIMEOUT.Time, @2 as CallId, @3 as EXITWITHTIMEOUT.QueueName, //Всегда 900 @4 as EXITWITHTIMEOUT.ChannelName, //@5 as EventType, @6 as EXITWITHTIMEOUT.Position, @7 as EXITWITHTIMEOUT.OrigPosition, @8 as EXITWITHTIMEOUT.WaitTime Resident QueueLog Where @5='EXITWITHTIMEOUT' and Exists(CallId, @2) ; TRANSFER: LOAD @1-ApplyMap('mapCallTime',@2,@1) as TRANSFER.TimeShift, //frac(@1/60/60/24) as TRANSFER.Time, @2 as CallId, @3 as TRANSFER.QueueName, //Всегда 900 @4 as TRANSFER.ChannelName, //@5 as EventType, @6 as TRANSFER.Extension, @7 as TRANSFER.Context, @8 as TRANSFER.HoldTime, @9 as TRANSFER.CallTime, @10 as TRANSFER.OrigPosition Resident QueueLog Where @5='TRANSFER' and Exists(CallId, @2) ; rem Проверяем, что не забыли еще какие-нибудь ивенты NONE: LOAD floor(@1/60/60/24+MakeDate(1970,1,1)) as NONE.Date, frac(@1/60/60/24) as NONE.Time, @2 as CallId, @3 as NONE.QueueName, @4 as NONE.ChannelName, @5 as NONE.EventType, @6 as NONE.1, @7 as NONE.2, @8 as NONE.3 Resident QueueLog Where @5<>'CONFIGRELOAD'// and @5<>'QUEUESTART' ; DROP Table QueueLog; /** for i=0 to 999; LET tab=TableName(i); IF len(tab)>0 then LET fn='Queue\' & tab & '.qvd'; STORE [$(tab)] into [$(fn)] (qvd); ENDIF NEXT i; LET i=; LET tab=; LET fn=; **/ |
Загрузив данные, мы можем начать увлекательное путешествие в мир очередей Астериска. В этом вам помогут выражения:
| Количество вызовов (звонков) | Count(DISTINCT CallId) |
| Сорвалось вызовов | Count(ABANDON.WaitTime) |
| Клиент ждал и не дождался (с) | Sum(ABANDON.WaitTime) |
Собственно, вот и наше жемчужное зерно — теперь мы знаем, сколько вызовов сорвалось, поскольку клиент не хотел ждать. При желании можем построить зависимости времени ожидания и т.п.
Немного занудства
Не забудьте, что время голосового приветствия или голосового меню (IVR) в это время не входит, поскольку клиент попадает в очередь позже. Таким образом, если среднее время ожидания сорвавшегося клиента 17с, а длительность голосового приветствия, 22с, то полное время ожидания — 39с.
МоноЛог
Скептики возразят: «Но ведь могли звонить и старые клиенты, которые нас знают, любят и готовы перезвонить позже! Возможно, они и перезвонили позже, но модель данных не позволяет просто сделать анализ в разрезе номера вызывающего абонента»
Общение с продавцами и руководством, выявило очевидный факт – им неинтересно смотреть, как звонок гулял по очередям, им важен простой ответ на вопрос: ”разговор состоялся?” — “да“ или “нет“. Поэтому от модели звезды решили отказаться в пользу простой таблицы. К тому же, мы хотели подключить к информации о звонках информацию о продажах.
Очередная версия модели данных резко упростилась до единственной таблицы:
Немного оправданий
Мы немного изменили названия полей, ибо CallTime без контекста может означать и время разговора, и его длительность. CallID и CallerID – неудачные названия, они визуально близки и могут вызывать ошибки, но наши пользователи уже к ним привыкли.
Контрагент.Код — код контрагента в 1С (определяем по номеру телефона, у нас, как вы догадываетесь, 1С и в ней живут списки телефонов контрагентов)
Line – входящая линия
CallID – идентификатор звонка
CallDate – дата звонка (вынесена в отдельное поле, для уменьшения вариабельности данных)
CallTime – время звонка (вынесено в отдельное поле, для уменьшения вариабельности данных)
CallHour – час звонка, для контроля загрузки в течении дня (позже перерастет в мастер-календарь)
CallerID – номер вызывающего абонента
CallerAge – возраст клиента, в данном случае если есть в 1С, то старый, если нет — новый
CallDuration – длительность вызова
ServiceDuration – длительность разговора, если время разговора равно 0, значит клиент сорвался.
Вот кусочек кода, заранее извиняюсь за активное использование mapping, он позволяет снизить неоднозначности, упомянутые выше:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
REM Грузим логи в память для ускорения; QueueLog: LOAD rowno() as RecID, // на всякий случай, чтобы различать одинаковые записи @1, text(@2) as @2, @3, @4, @5, @6, @7, @8, @9, // может быть непустым!!! @10,// может быть непустым!!! @11 //@11 должен быть всегда пустой FROM [Queue_log\queue_log.*] (txt, utf8, no labels, delimiter is '|', msq) ; rem Формируем список внешних звонков; ExternalCalls: LOAD DISTINCT @2 as ExternalCallIDs Resident QueueLog Where @5='ENTERQUEUE' // Входим в очередь and len(@7)<>3 // исключая внутренние 3-Х значные звонки ; rem Подбираем данные о старых клиентах из 1С; tmpCallers: LOAD numa, Контрагент.Код FROM [ТелефоныКонтрагенты\*.csv] (txt, utf8, embedded labels, delimiter is ',', msq) WHERE len(numa)>0; mapCallerAge: MAPPING LOAD numa, 'Старый' as numa_age RESIDENT tmpCallers; mapCaller1СID: MAPPING LOAD numa, Контрагент.Код RESIDENT tmpCallers; DROP TABLE tmpCallers; mapCallID2Line: Mapping LOAD @2 as CallId, if(len(@6)>0,@6,'---') as Line Resident QueueLog Where @5='DID'; mapCallID2CallerID: Mapping LOAD @2 as CallId, if(left(@7,1)='8' and len(@7)=11, '7' & mid(@7,2),if(len(@7)=10,'7' & @7, @7)) as Line Resident QueueLog Where @5='ENTERQUEUE' and len(@7)>0 and @7<>'unknown'; mapCallID2Caller1CID: Mapping LOAD @2 as CallId, applymap('mapCaller1СID',if(left(@7,1)='8' and len(@7)=11, '7' & mid(@7,2),if(len(@7)=10,'7' & @7, @7)),'---') as Line Resident QueueLog Where @5='ENTERQUEUE'; mapCallID2CallerAge: Mapping LOAD @2 as CallId, applymap('mapCallerAge',if(left(@7,1)='8' and len(@7)=11, '7' & mid(@7,2),if(len(@7)=10,'7' & @7, @7)),'Новый') as Line Resident QueueLog Where @5='ENTERQUEUE'; mapCallID2Duration: Mapping LOAD @2 as CallId, @7 as Duration Resident QueueLog Where @5='COMPLETEPICKUPER' or @5='COMPLETEAGENT' or @5='COMPLETECALLER'; mapCallID2EndTime: Mapping LOAD @2 as CallId, max(@1) as EndTime Resident QueueLog Group by @2; Asterisk: LOAD *, Applymap('mapCallID2Line',Asterisk.CallID,'---') as Asterisk.Line, Applymap('mapCallID2Duration',Asterisk.CallID,0) as Asterisk.ServiceDuration, Applymap('mapCallID2CallerAge',Asterisk.CallID,'Новый') as Asterisk.CallerAge, Applymap('mapCallID2Caller1CID',Asterisk.CallID,'---') as Контрагент.Код, Applymap('mapCallID2CallerID',Asterisk.CallID,repeat('0',11)) as Asterisk.CallerID ; LOAD DISTINCT Date(Floor(@1/60/60/24+MakeDate(1970,1,1))) as Asterisk.CallDate, Time(Frac((@1-43*365*24*60*60)/60/60/24)) as Asterisk.CallTime, Hour(frac(@1/(60*60*24))) as Asterisk.CallHour, @2 as Asterisk.CallID, applymap('mapCallID2EndTime',@2,@1)-@1 as Asterisk.CallDuration ; LOAD min(@1) as @1, @2 Resident QueueLog Where @5='DID' and @3<>989 // говорят что 989 - это тестовая линия and @3<>150 // логисты //and @3<>200 // Отдел продаж ,, //and @3<>300 //операторы and @3<>400 // бухгалтерия //and len(@6)>0 // Исключая внутренние звонки and Exists(ExternalCallIDs, @2) GROUP BY @2 ; DROP TABLEs ExternalCalls, QueueLog; |
Можно использовать выражения
| Входящих звонков | Count(Asterisk.CallID) |
| Входящих звонков с различных телефонов | Count(DISTINCT Asterisk.CallerID) |
| Пропущено звонков | Count({<Asterisk.ServiceDuration={0}>} Asterisk.CallID) |
| Упущено абонентов | Count({<Asterisk.ServiceDuration={0}>} DISTINCT Asterisk.CallerID) |
Используя измерение Asterisk.CallerAge удобно смотреть доли новых и старых клиентов. После интеграции этой таблички в систему отчетности, появилась возможность строить разрезы связанные с клиентами (ОсновнойМенеджерКонтрагента, Регион, Приоритет и т. п.), а так же анализировать частоту звонков и заказов.
ЭпиЛог
Первая версия модели данных (звезда) была подготовлена за день, только на основании предоставленных логов. Ранее с Астериском были не знакомы, пришлось изучить описание событий его очередей. Буквально к концу рабочего дня было показано, что за месяц мы теряем несколько сотен звонков поскольку клиент не дожидается ответа — ранее такой аналитики мы не вели.
Изучение работы очередей, заняло еще день, но стало понятно, что модель звезды неудобна пользователям, они складывают время всех событий RINGNOANSWER, получают мультипликативно завышенный на количество операторов результат, и говорят, что QlikView неправильно считает. Поэтому еще один день заняло создание модели с нуля, в виде понятном пользователю, заодно к ней прикрутили признак клиента, позволяющий определить старый он или новый.
Анализ показал, что в пропущенных звонках соотношение клиентов старый/новый 2:1. Кто бы мог подумать, но:
- доля тех, кто сумел после этого дозвониться, в старых клиентах, выше чем в новых,
- ждут в очереди, старые клиенты дольше, чем новые.
- тем не менее более сотни клиентов (новых и старых) за месяц так не перезвонили нам.
Вот они живые заказчики, вот их номера телефонов! Вот работа для SuperManSalesManа! Вот она, реальная отдача бизнес аналитики!
Немного оптимизма
Осталось обширное поле для оптимизации IVR, изменения настроек и структуры очередей, мы хотим разделить очереди для старых и новых клиентов (тем более, что Астериск это позволяет) и назначить им разные приоритеты, старых клиентов сразу переключать на персональных менеджеров, реализовать автоматический call-back по недозвону.
Вы тоже можете попробовать улучшить ваш бизнес с минимальными затратами ресурсов даже с помощью бесплатной QlikView Personal Edition.
Примеры данных и скриптов выложил на GitHub.
Расскажите, а как ваши маленькие проекты (до 7 дней) помогли (могут помочь) вашему бизнесу?



{kind=link}
Свежие комментарии